
Recently, I have been part of the TechNation LawTech workshops with Clausematch. Our joint efforts were aimed at showcasing how to achieve “digital transformation” and “regulation into code” in practice. The project turned out to be successful, so I would like to share our experience and key results here.
Keeping track of changing regulations is one of the biggest challenges regulated firms face today. Whether it’s the banking industry, the insurance industry, or the legal industry, it’s not easy for businesses to keep up with the vast number of changes in the regulatory space. Monitoring the constant changes can quickly become a burden for an organization. For firms that operate on an international scale, the challenges are immense. These firms need to keep track of changing regulatory obligations in different jurisdictions, with rules written in different languages and using different taxonomy.
One solution to this problem is digital, machine-readable regulation, which forward-thinking regulators and RegTech firms are now focusing on. Imagine regulators who could automatically place tags using their taxonomy in any regulatory text. Or even something bigger - a company that could automatically apply a regulator’s taxonomy to its standards and policies. All of a sudden, it would be much easier to find, correlate, and interlink relevant regulatory content. Life would be much easier for both regulated firms and regulators.
Digital compliance obligation detection: Our experience in the LawTech Sandbox
In an effort to develop a digital regulatory obligation detection solution, Clausematch recently participated in the LawTech Sandbox Pilot. The LawTech Sandbox is an initiative from LawtechUK designed to fast-track transformative ideas, products, and services that address the legal needs of businesses and society. It provides pioneers with access to tools, services, and people that can help accelerate the development of game-changing LawTech solutions.
Our goal during the LawTech Sandbox was to find and showcase the way to digital regulation. Let’s say a firm wants to instantly obtain all of their compliance obligations from new or old regulation, but there are thousands of pages of unstructured regulatory text. Is there a way to overcome the challenge and structure all of the content in a specific way?
Digital transformation in action: Teaching a neural network to tag
During the LawTech Sandbox, Clausematch proved that it’s possible to develop a machine learning-based compliance obligation solution. Speaking about it in tech terms, tagging is a standard NLP task, but until recent advancements, it was an immense challenge to effectively separate context-specific terminology in a high dimensional semantic space. Here’s a look at how we taught our neural network to tag:
- First, we uploaded a document onto the Clausematch platform.
- Then we defined the taxonomy structure for our use case with the experts.
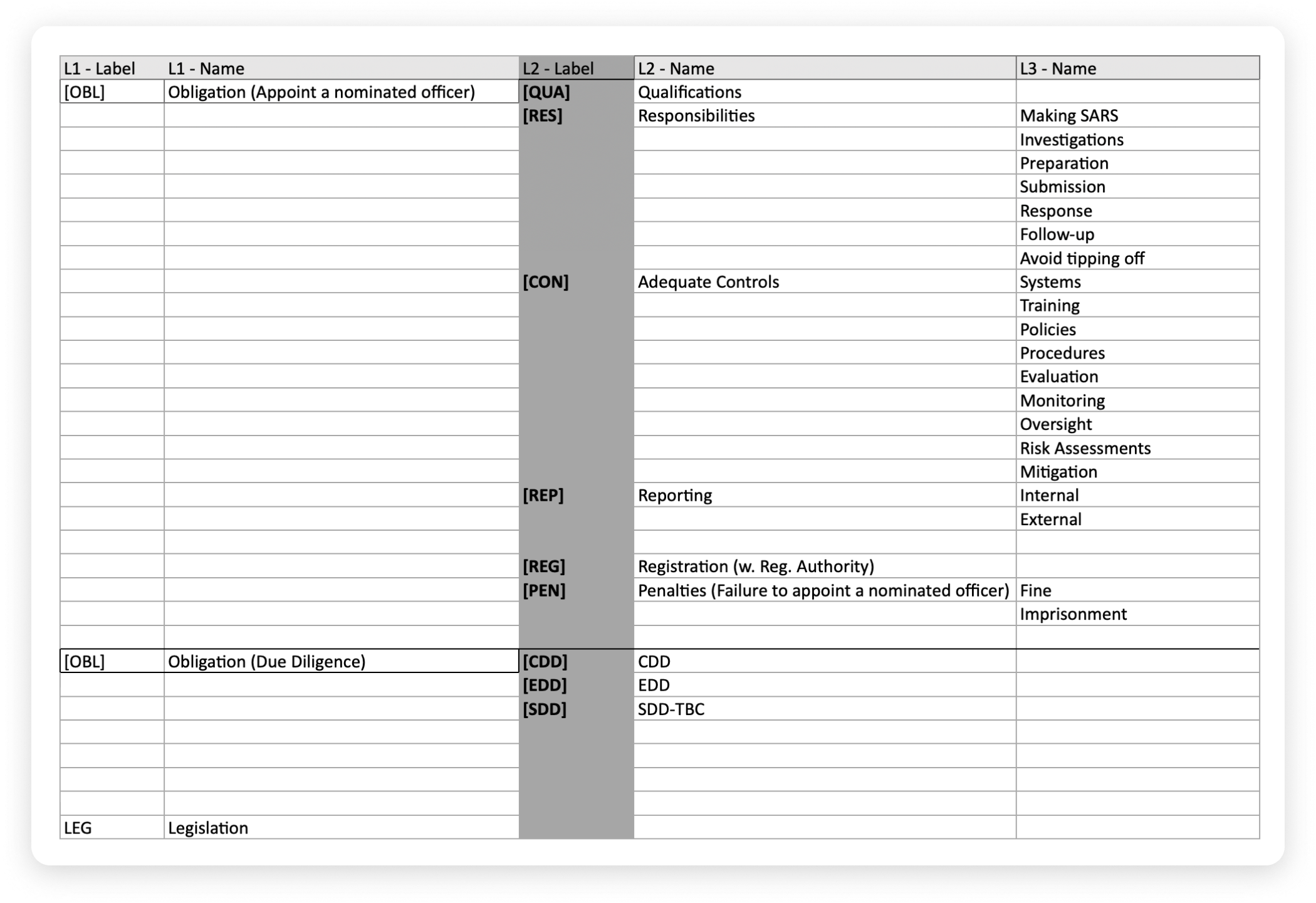
- Next, the experts labeled the entity with in-text tagging using Clausematch.
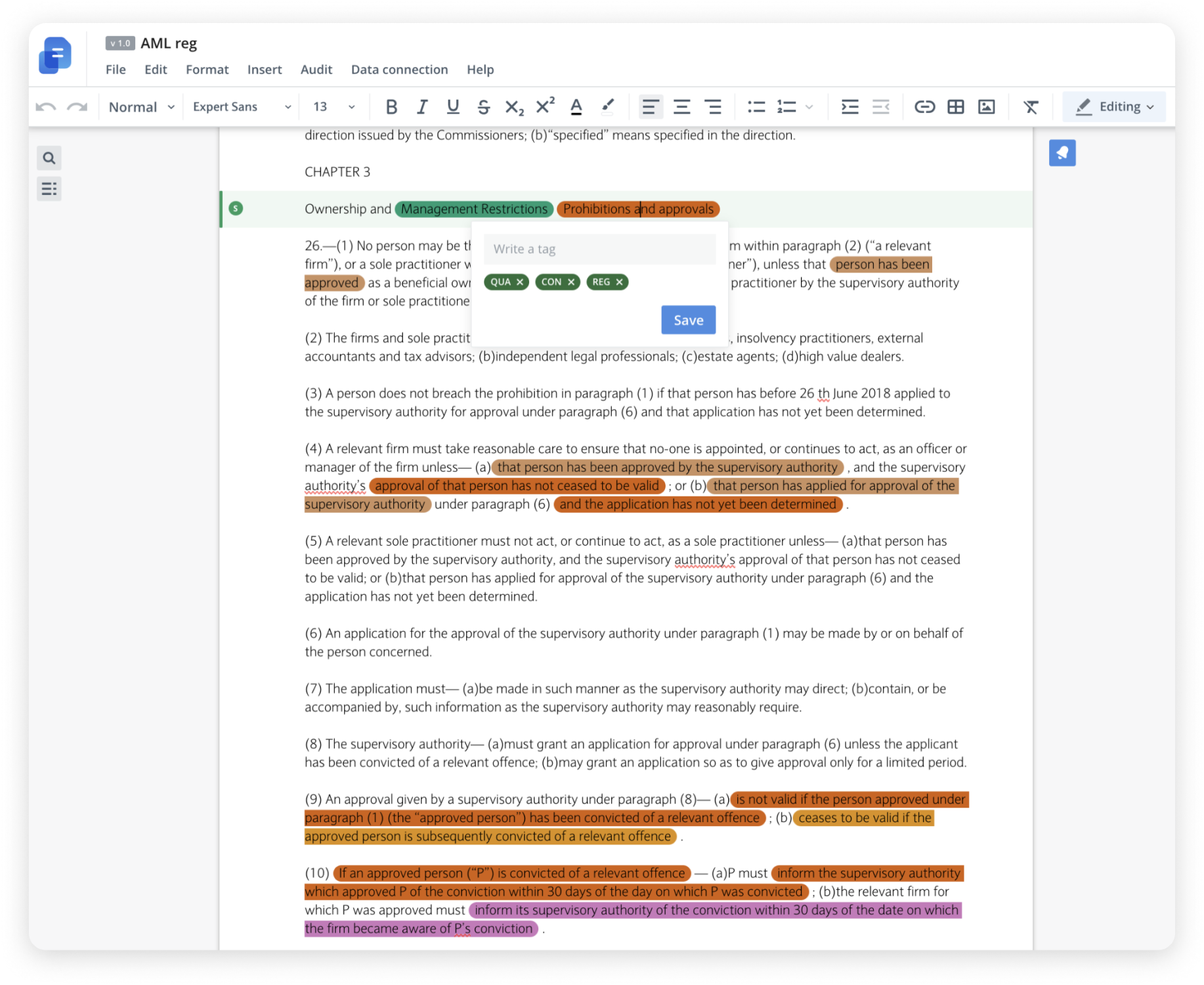
- We then let the machine-learning BERT-based model read through the text to train and capture the idea behind the concept.
- Then we applied the model to automatically tag a completely new document to verify the result.
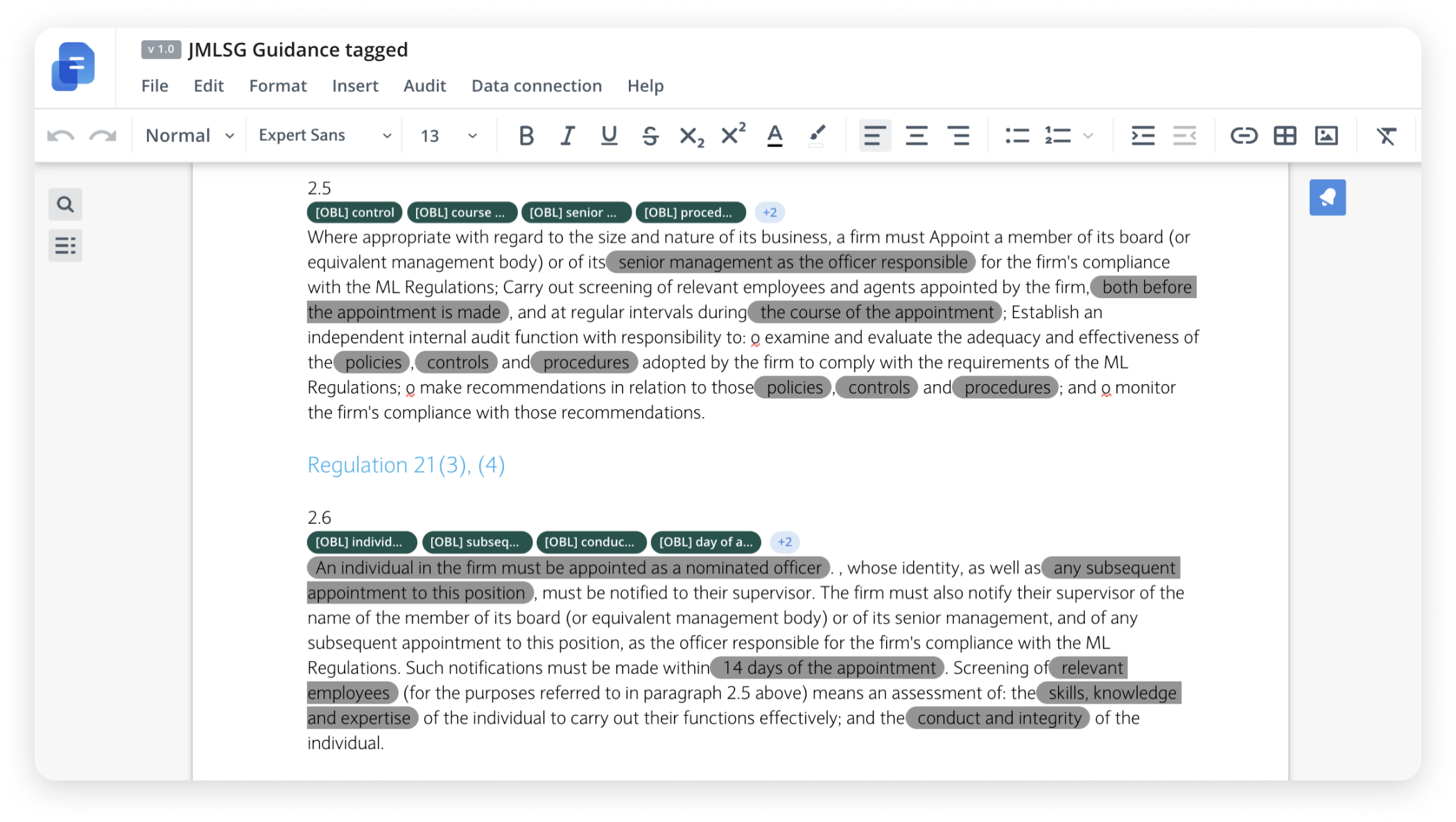
- Finally, experts did the evaluation of the result and revealed that the model's tagging was smart and it did capture relevant use cases that were not represented in the training dataset.
Challenges experienced
In the process of working with tags, we experienced several challenges.
Firstly, regulatory experts are required to complete steps two and three. The goal is to create a tagging dataset which is as representative as possible. Just like when an art expert has to acquaint himself with samples from each Pablo Picasso period before he is safe to say that he knows something about the painter, a data science expert is needed to guide the regulatory experts in order to optimize the tagging process.
For example, if a regulator says it may ‘suspend’ or ‘cancel’ a person’s registration, should that be two tags (suspend) and (cancel), or one tag (suspend or cancel)? The answer to this question is that it should be two tags, otherwise we may face a discrepancy with cancel or suspend, and an attempt to normalize it may result in a ‘suspend cancel’ tag, which may clash with other activities.
This is important since we extract tags not by rules, but with the machine-learning model. Therefore, we don't write patterns for desirable words but capture the semantic context of the tagged entity, and the model output then should serve as a unique identifier for a term with a co-create meaning, but now purified from the context variations. Thus, the structured result from the model's output will look like this: [REG: suspend] and [REG: cancel]. For more challenging examples, a named-entity linking (NEL) model is required as the next step for further result refinement. The overall architecture for the complete solution can be found here.
Secondly, a lot of text needs to be tagged. We tagged over 300 paragraphs to teach the model and about 2,000 paragraphs were required to define the different types of obligations. To compare this with the field of art, this is like defining the impressionism style, but not the exact artist. That would be the next level for the model. Right now, we are only capturing the first layer of tags. In the pictures above, this discrepancy is seen by the manual labeling done in different colors and the model output being in all grey.
Third, there are sometimes obvious inconsistencies in the regulatory documents.
Finally, a good tool is required for the process. It needs to support real-time changes from all contributors and remote access. It also needs to support the tagging and ML analytics of the documents – something that Google Docs cannot provide and adjust per each company.
Ultimately, the LawTech Sandbox and Clausematch’s technology enabled us to overcome these challenges. The Sandbox provided us with an opportunity to access top regulatory experts while Clausematch's technology capabilities allowed us to carry out the experiment.
What we achieved in the LawTech Sandbox
Overall, our results in the LawTech Sandbox were impressive. We were able to:
1. Create a model capable of understanding the regulatory obligation concept, i.e., transferring the understanding of obligation - the same way as you transfer the style of art paintings with an unseen invisible tag related, for example, to the nature and the length of any existing or previous relationship, thus applying CDD measures tag onto "nature and length of any existing or previous relationship", "apply CDD measures" (although there were no CDD acronym in the training data) "identification and verification of customers" - although there were only "identification and verification data" in the training dataset and it was not part of a tag there.
2. Transition to digital regulation. As a result of the experiment, we were able to create a basis for knowledge graphs, which are an important development for regulation as they provide consistent, structured analysis. We were also able to achieve standardization, mapping, and robotic automation (RPA). More information about the usage of knowledge graphs for digital transformation can be found here.
“The LawTech program was instrumental for us as it allowed us to develop solutions for challenges and problems that both regulators and regulated firms face. What was most unique about it was that it provided us with an opportunity to work with multiple regulators and have them come together at the round table all ‘in one room’, all at one time simultaneously, something that we were not able to do before. As part of the Sandbox, we were looking at several use cases such as anti-money laundering and KYC, ESG, privacy, and onshoring post-Brexit. Meeting experts allowed us to tap into a wealth of experience and deep-dive into the issues that the industry is looking at," said Anastasia Dokuchaeva, Head of Product at Clausematch.
Jenifer Swallow, Director of Lawtech UK, commented: "Moving from analog to digital compliance is an immediate and compelling opportunity for businesses and regulators alike. Increasing complexity and responsibility means the old approach to consuming and implementing regulation is fast becoming untenable and with capabilities like Clausematch, also unnecessary. It was fantastic to see the penny drop on this with so many collaborators during the Sandbox Pilot in very practical ways and to see the group work producing a dataset to enable the tool to be deployed across different types of regulation and compliance use cases.”
Digital regulation is the way forward
Today, organizations are still spending a great deal of time and money processing regulation manually. This is a real burden for many firms. Put simply, the ever-increasing volume of regulatory content being published is too much to keep up with.
Digital regulation is clearly the way forward. This approach to regulation offers huge benefits for regulated firms and regulators alike. In the years ahead, we are likely to see many more developments in this space.